PHI Exposure Guard
Stateful De-Identification
for Streaming Data
Re-identification risk builds across events, modalities, and time. Most de-identification pipelines treat each record as isolated and never see it coming. This system tracks cumulative exposure continuously and adjusts masking strength before it's too late.
Static masking is the wrong model
Standard pipelines treat every record independently. Detect PHI, remove it, move on. That works for single documents. It breaks in streaming systems where the same patient shows up across hundreds of events over time: clinical notes, ASR transcripts, imaging metadata, waveform headers.
A name fragment, a voice signature, a face region in an image proxy. None of these are identifying alone. Accumulated across a session, they are.
Per-document masking. No memory of prior events. Risk accumulates invisibly across the stream and no threshold ever fires.
Subject-level exposure state persisted across events. Rolling risk across modalities and time. Masking strength scales with actual accumulated risk.
Five masking tiers, one adaptive controller
Instead of a single policy applied to everything, the controller picks from five tiers based on a continuously updated risk score. Hover each tier to see the threshold.
The exposure state lives in a Dynamic Contextual Privacy Graph (DCPG), a per-patient, per-modality graph that accumulates PHI unit counts, tracks cross-modal semantic links (cosine similarity > 0.30), and applies recency weighting to the entropy calculation. Policy decisions are made by a PPO agent with an LSTM backbone, pre-trained over 200 stratified episodes.

DCPG node and edge structure. Each patient is a subgraph; nodes = PHI per modality; edges = co-occurrence and cross-modal semantic links.
What the numbers look like
Delta-AUROC measures how much masking degrades an adversarial re-identification classifier. Negative means the adversary is losing signal. Multi-run mean: -0.9167 +/- 0.0000 (95% CI, n=10). Same result across all 10 jittered runs. By the end of the stream the masked output carries almost no re-identification signal.

AUROC reduction over the 34-event stream. Peak protection at event 11: delta = -1.000.

Multi-run robustness across 10 jittered replications. Zero variance in final delta-AUROC.
Every static policy fails at least one side. Redact everything and utility collapses. Apply weak masking and privacy breaks at high risk. Adaptive is the only policy that clears the 0.85 privacy floor while keeping utility above 0.50 on the bursty workload.

Privacy @ High Risk vs Utility @ Low Risk. Adaptive uniquely satisfies both constraints on the bursty workload.
| Policy | Privacy @ High Risk | Utility @ Low Risk | Consent Violations | Latency (ms) |
|---|---|---|---|---|
| Always-Raw | 0.000 | 1.000 | 0 | 0.5 |
| Always-Weak | 0.004 | 0.847 | 0 | 1.0 |
| Always-Synthetic | 0.564 | 0.676 | 0 | 2.0 |
| Always-Pseudo | 0.855 | 0.440 | 0 | 1.5 |
| Always-Redact | 1.000 | 0.000 | 17 | 1.0 |
| Adaptive ★ | 0.991 | 0.847 | 10 | 1.09 |
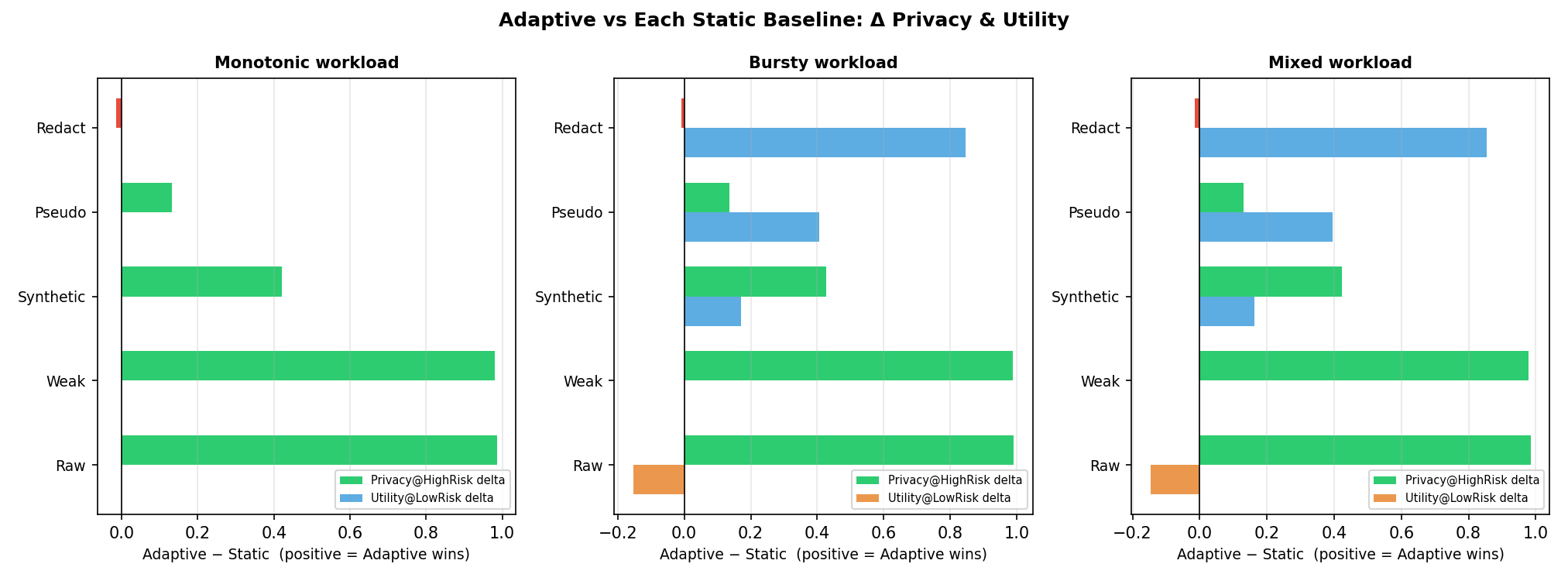
Delta vs each static baseline. Green = adaptive wins on privacy, blue = adaptive wins on utility.

Effective privacy and utility conditioned on risk level. Static policies cannot adapt across the full risk range.
Risk starts around 0.5 and climbs toward 0.97 by event 33 as PHI accumulates across patients and modalities. The policy switch timeline shows which tier is active at each event, with threshold crossings and consent-cap events annotated.
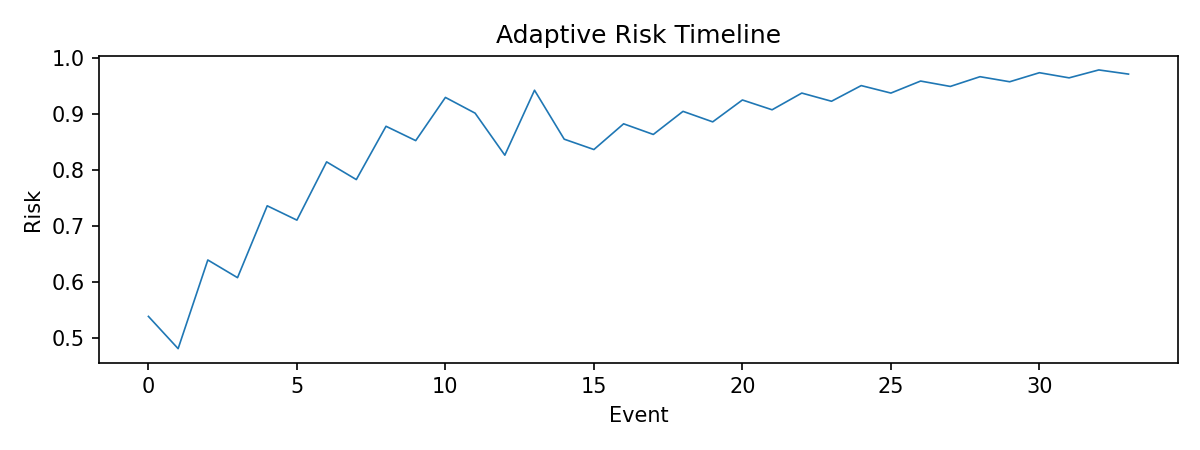
Cumulative risk score across all 34 live events.
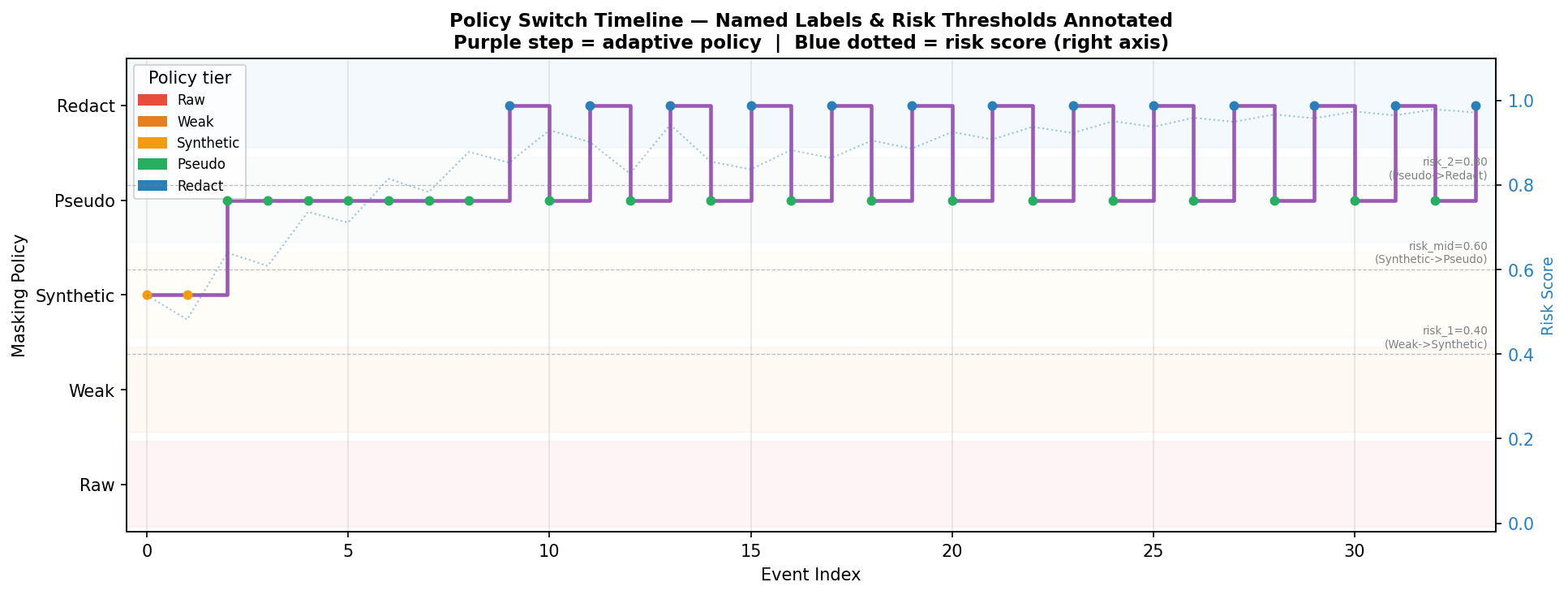
Policy tier per event. Consent-cap events show where redact decisions are downgraded to pseudo for patient A.

Risk model validation: exposure-entropy score vs combinatorial reconstruction probability. Pearson r = 0.881.
The obvious evasion: keep every event just below the lowest threshold. We modeled this formally. The attacker spaces PHI at risk 0.34-0.39 and sends a cross-modal probe every 5th event. The system detects it via cosine similarity, applies a +0.15 nudge, and escalates to pseudo on every probe event. Always-Weak never responds.

Formal adversarial model: sub-threshold PHI probing with cross-modal exploitation.

Adaptive escalates on every probe event. Always-Weak stays flat throughout.

Modality-imbalanced and alternating-burst workloads. Adaptive maintains the privacy floor across all three.
Canonical multi-run latency is 17.2-17.9 ms across pseudo, redact, and synthetic, well inside the 50 ms real-time threshold. Latency stays flat with respect to risk score, so the controller is not doing more work as exposure accumulates.

Per-policy latency. Multi-run means shown in red. Single-run warmup outliers excluded from canonical figure.
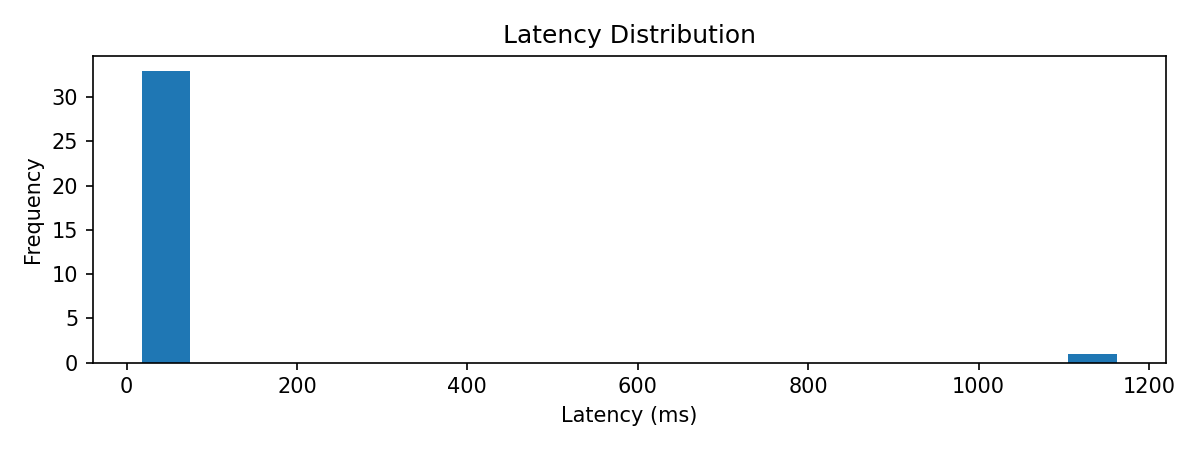
Overall latency distribution across all 34 live events. One warmup outlier visible near 1100ms.
200 stratified pre-training episodes before live deployment. By the final epoch, pseudo and redact make up a larger share of decisions, which is convergence toward risk-appropriate choices. Live-loop rewards settle into 0.62-0.67 after event 5.

PPO training stability: reward with rolling average and policy distribution across training epochs.
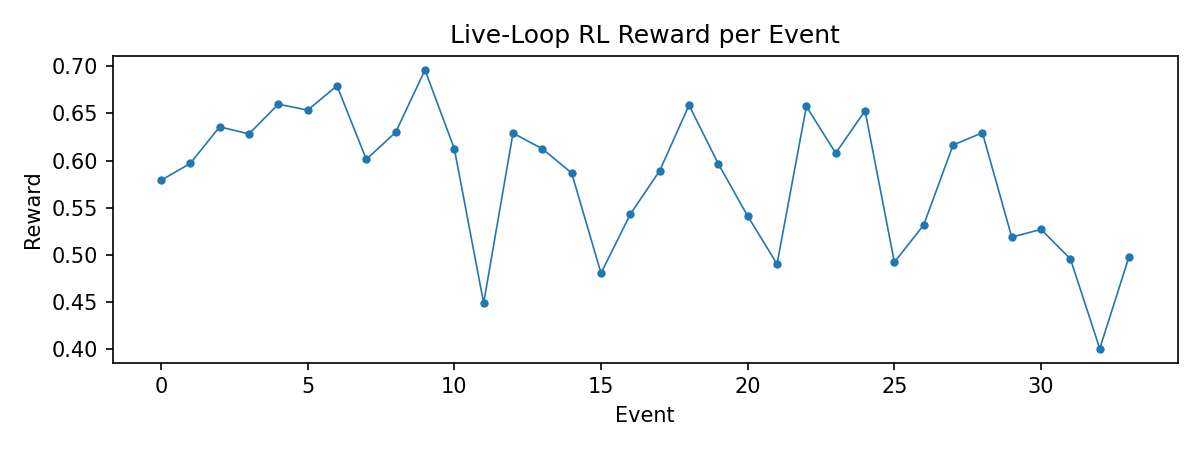
Per-event RL reward during the 34-event live loop.

Reward function fix: old alpha*(1-risk) term penalized the agent for high-risk environments. New risk-normalized term stays stable.
The DCPG state can be merged across edge devices using a CRDT. Two devices with overlapping patient observations converge to the same result regardless of update ordering.
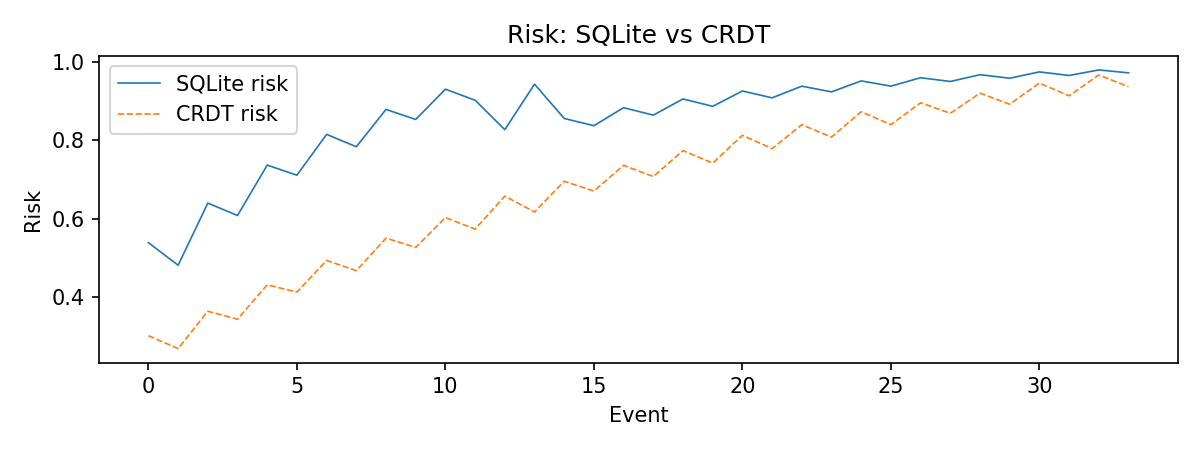
CRDT-backed risk vs centralized SQLite DCPG over the live run. Both converge toward 0.97 by event 33.
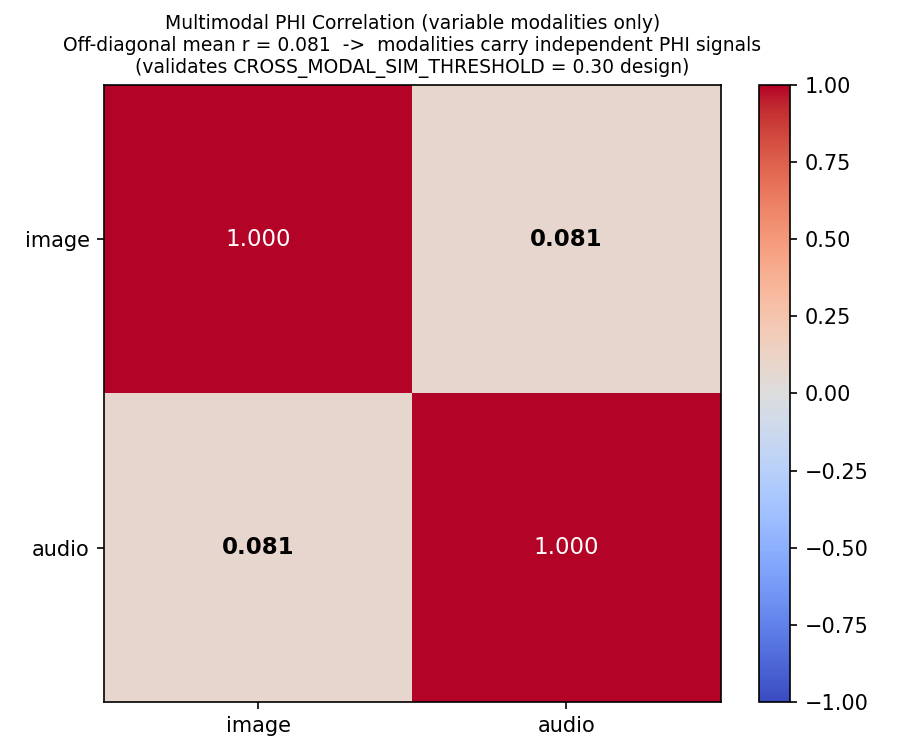
Cross-modal PHI correlation matrix. Off-diagonal mean r = 0.081, validating the 0.30 cosine similarity threshold.
Modular pipeline
PHI detection feeds the DCPG, which produces a risk score, which the PPO agent uses to select a policy, which the consent layer caps, which the masking CMO executes, all logged to a signed audit trail.
Try the scorer
Add events for a patient across modalities and watch risk accumulate in real time. State is shared across all users. Submit events for patient_001 and the next visitor picks up where you left off.
Suggested sequence: start with text, then asr with overlapping name and date strings. Watch cross_modal_matches fire on the second event. Keep going until trigger: true.
Run it yourself
Run the full benchmark locally. Results go to results/.
# install pip install phi-exposure-guard # run the benchmark python -m amphi_rl_dpgraph.run_demo # or run tests pytest -vv
Using this work
Cite via the CITATION.cff file in the GitHub repository, or use the BibTeX below.
@software{phi_exposure_guard,
title = {Stateful Exposure-Aware De-Identification
for Multimodal Streaming Data},
doi = {10.5281/zenodo.18865882},
url = {https://doi.org/10.5281/zenodo.18865882}
}